clap v3 Update: No More Strings
This is the second post in a series detailing the issues, progress, and design decisions used in clap v3. This post details removing the "stringly typed" nature of clap.
NOTE: This post uses String heavily, however, the actual clap code doesn't usually deal in Strings per se. Usually &str to keep from allocating more than absolutely required. But for simplicity sake, I'll be using String the majority of the time in this post.
Issue: Removing Strings
One of the biggest complaints about clap is the “stringly typed” nature of arguments. You give each argument a string name, and retrieve their value by string.
let arg = Arg::with_name("what could go wrong?"); matches.value_of("What could go wrong?"); You may have noticed I capitalized the W in the value retrieval, but not the definition....that's exactly what could go wrong!
To make matters worse if you typo a string name, you won’t know until you hit that code path. Combined with clap goes to decent lengths to ensure the clap::ArgMatches struct keeps memory usage low. This was originally done by stripping out any arguments which weren’t used at runtime. We also only store the bare minimum in clap::MatchedArgs instead of the full clap::Arg used during parsing. So while parsing may use more memory, if you want to keep the clap::ArgMatches struct around for a long time afterwards, you can.
A downside of that approach is this means the clap::ArgMatches struct doesn’t know if you typo’ed an argument, or it just simply wasn’t used at runtime. The solution would be keeping a list of all defined arguments in the clap::ArgMatches struct. However, for CLIs that have hundreds of arguments, the memory usage adds up quickly.
There are two (actually three) problems being conflated in this "stringly typed" issue:
- Users can typo argument names with no compiler help catching this (the can actually typo names in a number of places, definition and each individual access)
-
clap::ArgMatcheshas no knowledge of defined arguments and thus can't give appropriate errors if you do want to use strings, but typo one at value retrieval. - During parsing,
clapmust store, iterate, and compare all these strings many, many times which would be much more efficient with other types.
Let's take a deeper look at the problem, so we can see why it's so important to solve and some ways in which I'm working to solve it.
Challenge: Typo’ing Argument Names
The solution to this would be to allow users to use enum variants as argument names/keys instead of strings. This way the compiler can tell you, "no such enum variant exists" if you typo it.
The question then is how to store such a value in each clap::Arg (and clap) for parsing to be able to compare them. We can't define this enum in clap, it's defined in consumer code.
Another constraint I placed on myself, is I don’t want existing clap users to have to upgrade en masse. If you’re happy using strings, or you have a CLI that works, why spend the resources to change it. That means the design requirements are:
- Allow enum variants to be used
- The solution must also allow for strings to provide an easy upgrade path
Before I talk about the solutions I tried, and ultimately chose let me speak about the other challenges.
Challenge: clap::ArgMatches has no knowledge of defined arguments
If we take this issue into account, it'll add a third design requirement to our list:
- The solution is efficient enough, we can afford to store all defined arguments in a
clap::ArgMatches
Let's first look at the naive solution of storing strings, so we know our upper bound.
The clap::ArgMatches struct isn't defined exactly like this, but for brevity and underlying type clarity, it looks similar to this:
struct ArgMatches { args: Vec<(String, Vec)>, subcommand: Box ... } Note: You might ask why the Vec instead of a HashMap which this problem appears to beg for. That'll be covered in a future post ;)
Note 2: I put the subcomamnd field in this example, because it’s important to keep in mind the math we're about to do can explode if multiple levels of subcommands are used.
Example
Let's use an example case of a CLI which has 100 valid arguments, yet only two were used at runtime. We'll also assume this CLI has 25 possible subcommands at this current level. Yes, this would be a big CLI...but they exist!
Since a String in Rust is essentially a Vec, and a Vec is just a pointer plus length (usize) and capacity (usize). The memory looks roughly like this:
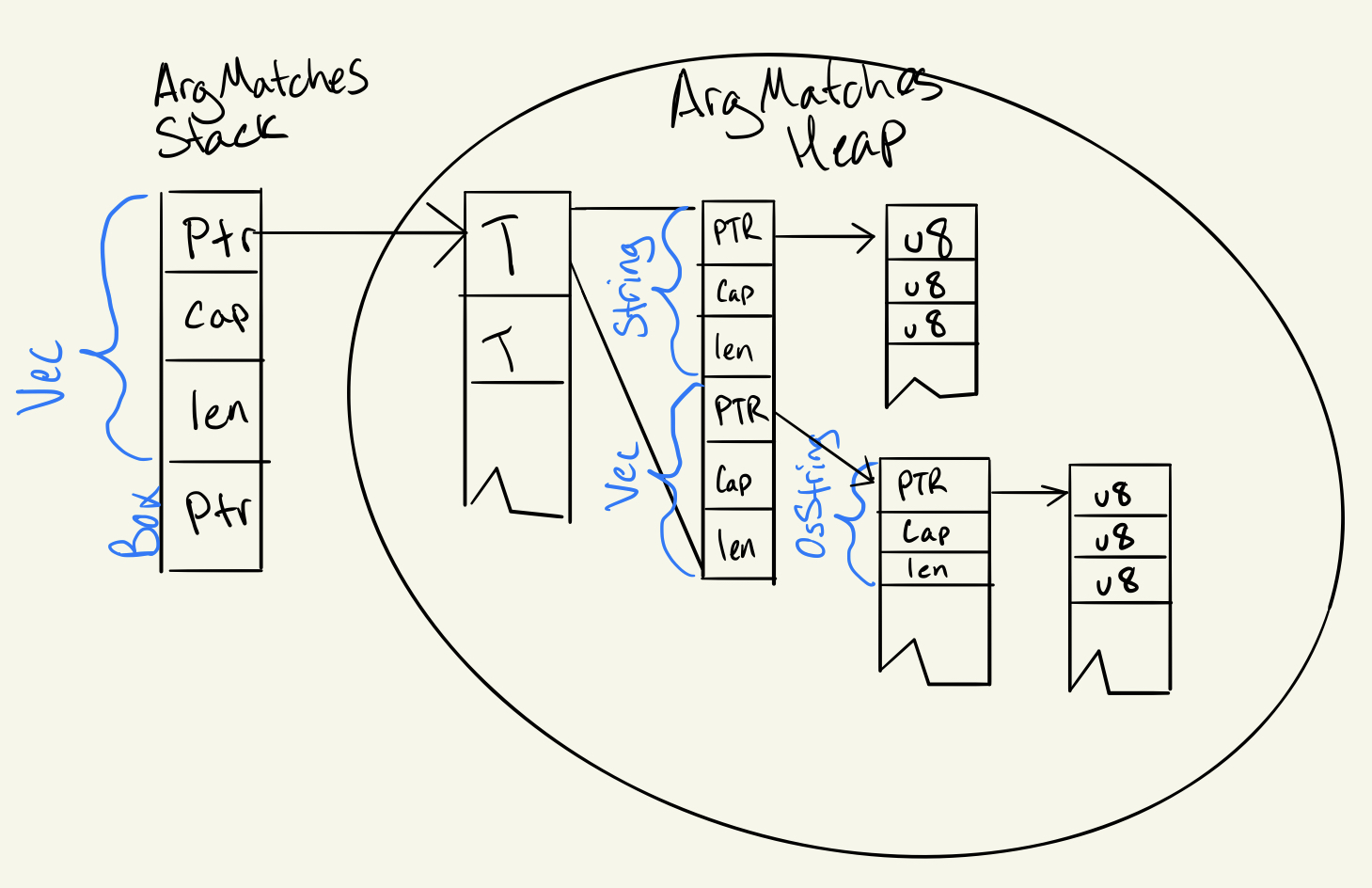
We're not going to worry about things like alignment and overhead, or minimum allocation sizes. We're only trying to get a rough baseline.
Looking at that we can determine each "used" arg constitutes about 72 bytes on the heap plus the lengths of the name (this doesn't take into account any "values" which would be additional). If we say each argument is on average 5 bytes of name (which is probably low), it would be 77 bytes not including values.
So storing two "matched args" vs 100 means the difference between 154 bytes vs 7,700 bytes allocated.
That’s just args. Then think about subcommands!
If we were to store all defined subcommands instead of a simple Box it becomes something resembling a Vec<(String, ArgMatches)> which doesn't change our stack too much (+16 bytes), but drastically increases the heap size. Again, assuming 5 bytes of name we get 25 * ((24+5) + 48 [a Vec+Vec]) = 1,925 bytes base (i.e. not including sub args).
We roughly have our baseline.
Challenge: Iterating and comparing strings is slow
This is probably the bigger issue than clap::ArgMatches heap size. Currently, iterating all the arguments using String comparisons is slow (relatively speaking).
I haven’t counted lately, but due to how parsing and validation occurs the number of times an argument gets compared is in the worst case order of (NUM_ARGS * NUM_USED_ARGS) * ~3ish. Concretely that means, if you use an average of 5 arguments per run, out of a possible valid 100, there are roughly 1,500 "touches" worst case. For CLIs like ripgrep which can have hundreds or thousands of arguments per run, the speed at which we compare and iterate arguments is important!
Whatever solution we go with, iterating clap::Arg structs (and thus whatever this new field is) should be faster than iterating and comparing a bunch of Strings. Since we’ve already gone over the math and breakdown of a String (24 bytes), we know it involves a heap lookup, so if we can avoid dereferencing to the heap that’d be gravy.
Solution 1: Generics
My first attempt at solving this was to use a generic type bound on PartialEq. While implementing this, I had an icky feeling though. All my type signatures were changing to clap::Arg which expands out to clap::ArgMatches. This has a few unfortunate side affects:
- People would have to annotate their types, making upgrading to
clapv3 a pain -
Tmight be huge, which doesn’t fix theclap::ArgMatcheslow memory requirement -
clapcodegen booms because you might have multipleT’s throughout your CLI (this is problem for one of the later challenges) (IIRC, Rust still doesn't strip unused monomorphized functions from the resulting binary...sad face)
So this doesn’t seem like a good route. Next I tried Trait Objects
Solution 2: Trait Objects
So what if instead of a type T: PartialEq I just stored trait object (&’a PartialEq or Box)? This fixes the problem of T being huge on the stack, because now T is just a pointer (8 bytes), and a vtable pointer (another 8 bytes). It also fixes the type signature as people still would just use clap::Arg.
However, I’m still touching the heap additional times each time I want to compare or find an argument.
I put this on the back burner as a maybe...as in maybe better than Strings, but still not ideal.
Solution 3: Hashing
What if I simply hash T and get a consistent output (I picked u64, or 8 bytes)?
Sure, I’ll have to hash all 100 T’s at definition time, but clap iterates and compares each argument far more than once per argument. So it seems a small price to pay, especially if I only need a fast hashing algorithm instead of a super secure one.
So I picked a FNV hash implementation which is fast. Hashing a T using FNV is only a few ns for all the types of T I tested. Using this, clap::Arg can now store an id: u64 (8 bytes vs the 24 bytes of a String), iterating and comparing a bunch of u64’s is significantly faster than a bunch of Strings.
This has a gigantic benefit that whenever clap internally needs to keep a list of arguments for some reason or another (requirements, validation fails, whatever) it can store a quick Vec instead of strings! This compounds the performance benefits.
If we go back to our example, the ArgMatches struct would now resemble:
struct ArgMatches { args: Vec<(u64, Vec), subcommand: Vec<(u64, ArgMatches)> ... } This looks more like:
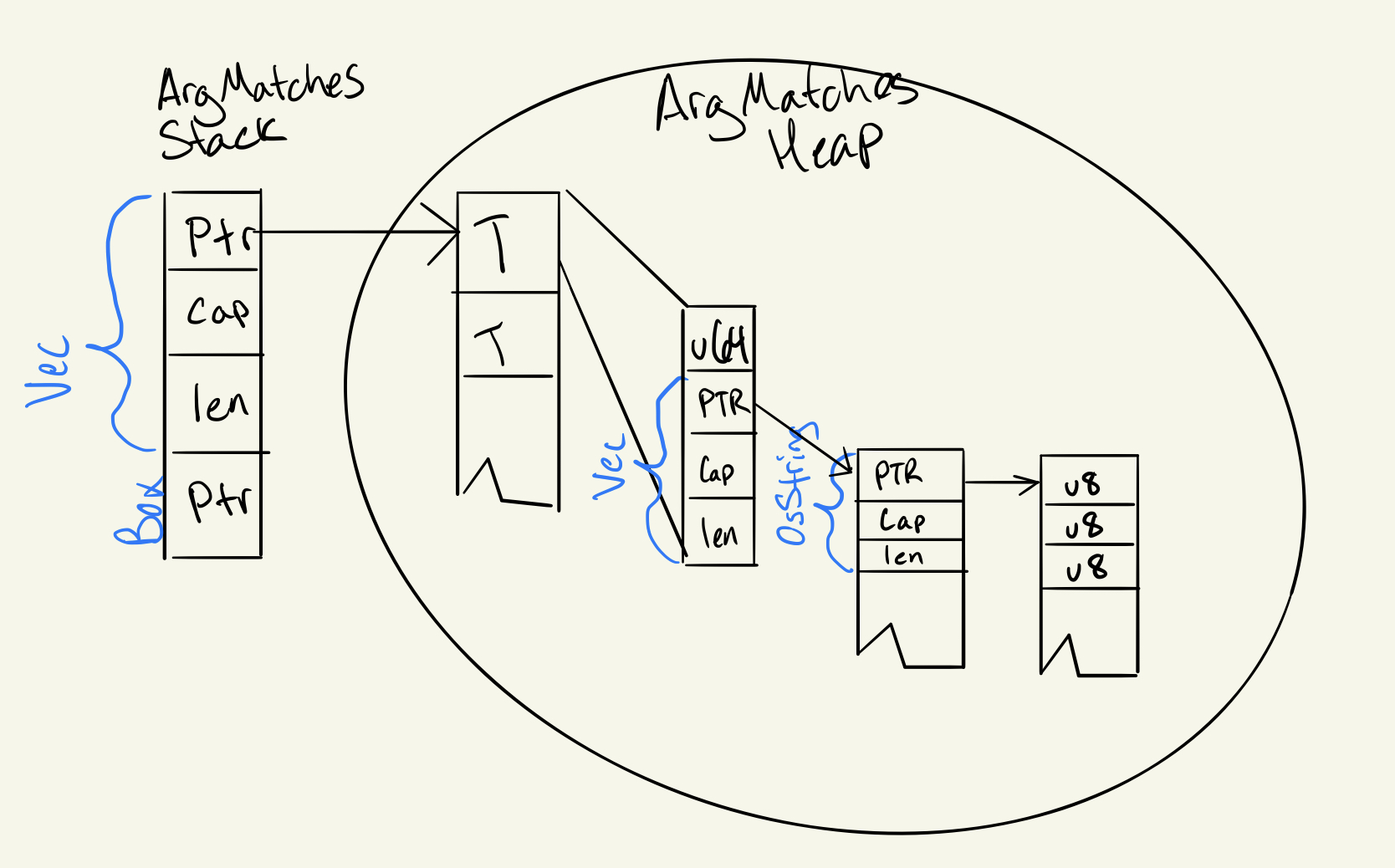
This 16 bytes per argument, plus a dereference, plus however many bytes made up the name. We used 5 bytes as a simple example, but some arguments have far more than 5 bytes.
Then thinking of subcommands, we save the same (16 bytes per subcommand, plus however many bytes per name). Using that 5 bytes of name just to make the math easy, this accounts for a saving of about 2,650 bytes. (Granted, we're still allocating more than the current clap v2. So you'll see in the status, I'm undecided if this is worth it.)
The biggest downside is each retrieval must now must be hashed in addition to definition. The reason I’m OK with this is access is much less frequent, and typically only happens once. So assuming 100 arguments, we’re comparing 200 hashes (100 for definition and 100 for access) with that of storing, iterating, and comparing a larger heap based type way more than 200 times.
Again, we're talking very, very big CLIs and worst case scenarios.
Status
I’m in the middle of implementing this change. It’s somewhat conflated with re-working how the parsing happens in order to be more efficient. This is the last major change prior to releasing v3-beta1 which I’m hoping will happen in the coming weeks/month.
I've done several refactors for the different scenarios discussed, and written TONS of benchmarks across a wide variety of possible workloads. The hashing solution is by far the fastest and most widely applicable.
I'm still not sure if I will include a list of all defined arguments in the clap::ArgMatches struct though. Switching away from using Strings as names solves the issue of a typo being confused with not-defined. If the argument isn't in the clap::ArgMatches struct, it was used at runtime. Simple.
The only advantage to including the valid arguments in an ArgMatches struct would be for those still using Strings. I'm leaning towards the unwillingness to switch from Strings shouldn't mean a performance hit for all. We'll see.
Next
In the next post I'll be detailing code bloat!