eBPF and Rust (Part 2)
This is a multi-part series on my adventure into eBPF with Rust.
In Part 2 we go over the guide I wish I'd had before diving into eBPF.
Series Overview
- Part 1: we lay out the problem set
- Part 2: we dive into eBPF in a general sense to familiarize ourselves with the technology before reaching out to Rust
- Part 3: we look at current state of eBPF networking in Rust and what it would look like to solve our Part 1 problem
-
Part 4: We do a deep dive into the current networking implementation of
redbpf-probesand note areas we want to improve - Part 5 (Coming Soon): We propose ideas for improving the
redbpf-probesnetworking modules
Future Kevin SaysBPF in general is a very deep topic about very low level details inside the Linux kernel. Here be dragons.ᕕ(╭ರ╭ ͟ʖ╮•́)⊃¤=(————-
eBPF looks incredibly promising and powerful. But there are are a ton of moving parts, and documentation is scattered on how all these parts interact and fit together (or don't). Most of this series I will be talking purely about eBPF and leave how it can be implemented to solve our problem for a later date.
About eBPF
BPF stands for Berkeley Packet Filter. It is a technology for running user code inside the Linux Kernel in a safe and efficient manner. BPF consists of a virtual machine running inside the kernel that takes BPF bytecode, optionally just in time (JIT) compiles the bytecode to native machine instructions, verifies its safety and ultimately runs the code.
History of BPF
Originally, BPF was use at the networking socket layer to inspect and filter network packets, hence the name Packet Filter. However, since that time BPF has grown in functionality began using the term extended BPF to denote the additional functionality and features. The "extended" terminology refers to BPF's new abilities to hook into the kernel at other arbitrary locations beyond just the network socket layer, as well as the ability to do more than just inspect and filter packets.
So is it BPF, eBPF, or cBPF?!
The creators of BPF and eBPF have since began calling the entire technology stack BPF for simplicity, and refer to the old BPF as cBPF (i.e. core BPF). It is common, if not somewhat confusing to see eBPF and BPF used interchangeably. This post uses BPF to refer to the entire technology stack, or what was previously known as eBPF and cBPF to refer to the core old BPF.
Whats so special?
One of the defining features of BPF is that it allows one to run arbitrary code inside the kernel upon various events. This is vastly more permanent than a pure userspace program which must request that kernel copy data between it's memory and the userspace memory over and over. Not only is copying the data expensive, but simply switching contexts back and forth from userspace to kernel space is very costly. Allowing arbitrary code to run kernel space without a context switch, and only copy the minimum required data to userspace can increase performance by orders of magnitude.
This complexity only increases when the frequency of the event is high. Imagine trying to do userspace network packet processing where the computer may receive millions of packets per second. Not needing to constantly switch back and forth between userspace and kernel space, or having to copy the memory regions over and over can save huge amounts of time.
Traditionally, in order to avoid the performance hit of userspace code doing this kind of work one would only be able to do so by re-compiling the kernel with custom code, or by creating a kernel module. Additionally, both re-compiling the kernel with custom code, and kernel modules allow writing unsafe code that could corrupt or otherwise crash the kernel.
BPF code, however, must run through a verifier prior to being loaded into the kernel and executed. This means the only code allowed to run is 100% verified safe (barring verifier bugs).
Components
Using BPF programs typically requires a few items:
- The BPF program source (which is usually a subset of C, but there are other languages adding support as well...more on this later)
- The BPF program (bytecode) itself stored in ELF binaries if pre-compiled from the step above, OR a userspace program which handles compiling the source language into BPF bytecode for the next step
- A userspace loader program which loads the BPF bytecode into the kernel for verification/JIT compiling/execution
- (Optionally) A userspace program which coordinates with the BPF program, either reading output for further processing or sending input
The steps to run a BPF program are somewhat along the lines of:
- Write BPF source
- Compile BPF source to an ELF binary
- Load the BPF code from step 2 into the kernel
- The kernel verifies the code is safe
- The kernel (optionally) JIT compiles the code
- The kernel executes the BPF code on some event
- (Optional) the BPF code communicates with a userspace program for either input or output
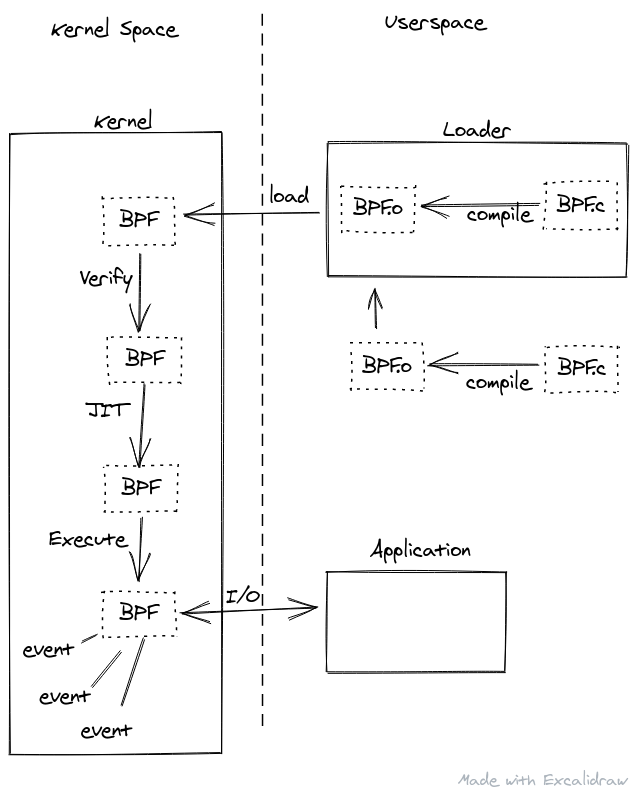
Because BPF programs normally need to be compiled from their source into BPF bytecode on the same machine in which they are going to be run, it is also common to have a single userspace program include the BPF program source inline and steps 2 and 3 are combined into a single userspace program where the loader will also compile the source before loading. In other cases the userspace program that loads the BPF object will also be the program that does the I/O.
BPF programs must be compiled on the machines in which they will be run on, unless the kernel versions and software stack match exactly. Because BPF relies kernel internals, if the BPF source is compiled on a machine with a different kernel version, or using a different compiler version, there can be misalignment and things are not guaranteed to function.
A new technology has emerged called BTF (BPF Type Format) and CO-RE (Compile Once, Run Everywhere) spearheaded by Facebook which allows a BPF program to be compiled on any machine, and run elsewhere so long as the host machine (where the BPF program is loaded/run) meets the kernel requirements of the BPF program itself. This is one way to alleviate the need to include compilers and development header files on the host machine, which is many times a production machine. BTF/CO-RE are still in early days and thus is not exactly perfect yet. It is still easiest to compile the BPF source on the host machine, or at least have a duplicate of the host machine where the BPF source can be compiled.
More Details
As alluded to above, the most common use of BPF is to have the BPF program running inside the kernel performing some kind of processing/accounting upon specific kernel events and then copying raw or minimally processed data to userspace for further processing and actions that would be too expensive to do in the kernel directly.
Also, as mentioned above because BPF programs must be 100% verifiable, it means that certain actions are deemed unsafe and not allowed to be used hence why a subset of C is used. This subset disallows things such as (but not limited to):
- No pointer arithmetic or comparisons (except for the add/sub of a value that is not derived from a pointer value)
- No pointer arithmetic that is out side the bounds of known-safe memory regions (i.e. maps, or network packet memory)
- No pointer values can be returned from maps, nor can they be stored in maps, where they would be readable from user space
- No function calls (unless fully inlined)
- No reading of uninitialized data (including registers; in fact the verifier will deny the mere presence of uninitialized memory, even if it's not read)
- No unbounded loops (all loops must be either fully unrolled, or have a known relatively low max iteration)
The verifier also requires all pointers to be checked against null prior to dereferencing. There are other limitations such as the total number of instructions in a BPF program, but most of these are either somewhat arbitrary and being lifted or so loose that they are not actually very restrictive in practice.
Newer kernels have loosened verifier restrictions such as some kinds of function calls and higher loop bounds as well as higher instruction counts, etc.
Help me please
With all these restrictions, how could one possibly write a useful program? This is where the communication with userspace "helper" programs exist. BPF programs usually do a small amount of work, either collecting data on various kernel structures, or event traces and copy the minimum required data over to userspace (remember the copy of memory is expensive) where the unbounded userspace program can do additional processing and accounting. It's not uncommon to have multiple BPF programs working in tandem with a single userspace program who is collecting data and events from all these BPF programs and presenting them to the user in some meaningful way.
BPF programs may also take input or cues from userspace programs, thus the I/O is bi-directional. All BPF I/O with userspace occurs via special structures call maps. These maps function like standard hash maps, or arrays and allow reading/writing of arbitrary data. These maps can be shared with other BPF programs, or userspace programs for communication and accounting purposes. Some special maps can also be pinned (shared) globally (i.e. exist even after the BPF program exits) or even on special file systems to be read/written to similar to standard files albeit with special programs that understand the map formats and how to properly read and write to them.
Once a BPF source program is compiled into bytecode, it's stored in a standard ELF binary along with any map definitions. The bytecode and map definitions are stored in special ELF sections so they can be found and loaded by the loader. These binaries may also contain relocations and other such standard ELF items, which the loader must be able to handle prior to loading the BPF code into the kernel.
This post won't go over ELF binary object files in detail, but at a high level object files are divided into "sections" where different types of data is stored in various sections. All sections have names, some are special pre-defined names so things like the OS know how to handle the data in them, and were to look while others are arbitrary and used to make the code execution easier or more efficient.
When you compile and link a program, the compiler and linker will assemble the ELF binary by placing things like executable code (functions) in special sections like .text, or initialized static variables into sections like .rodata. Logically they can be thought of like this:
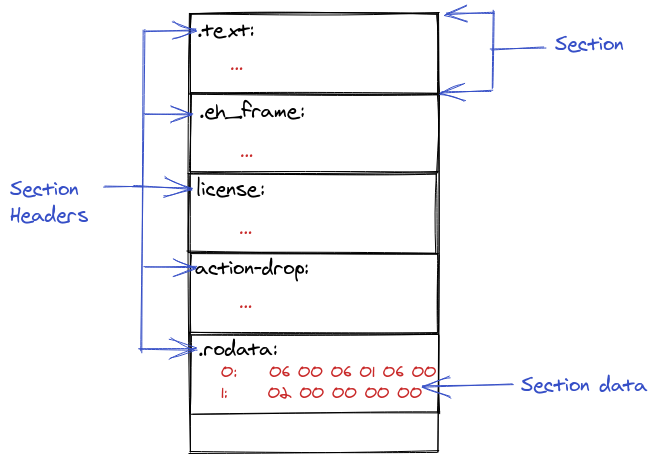
You can see the section header names of an ELF binary using tools like objdump, for example with assuming a fictional ELF name bpf.o we could do:
$ llvm-objdump -h bpf.o bpf.o: file format elf64-bpf Sections: Idx Name Size VMA Type 0 00000000 0000000000000000 1 .strtab 00000192 0000000000000000 2 .text 00000000 0000000000000000 TEXT 3 classifier 00000680 0000000000000000 TEXT 4 .relclassifier 00000040 0000000000000000 5 action-mark 00000088 0000000000000000 TEXT 6 .relaction-mark 00000010 0000000000000000 7 action-rand 00000098 0000000000000000 TEXT 8 .relaction-rand 00000010 0000000000000000 9 maps 00000048 0000000000000000 DATA 10 license 00000004 0000000000000000 DATA 11 .eh_frame 00000070 0000000000000000 DATA 12 .rel.eh_frame 00000030 0000000000000000 13 .symtab 000003d8 0000000000000000 Exposed by the Kernel
The manner in which the BPF API surface is exposed by the kernel is via system calls (bpf(2)), which in and of themselves are not very ergonomic to work directly with. Thus various "wrappers" have popped up to provide a more coherent and ergonomic API to work with. The Linux kernel provides one such wrapper library, which includes a loader and map definitions (in libbpf). The Linux source also provides several "bpf helpers" (bpf-helpers(7)) which make additional functionality easier to work with. Some of these helpers are licensed under specific terms only available to BPF programs licensed under the same or compatible terms, as verified by the kernel at load time.
With two distinct exceptions, the kernel provided libbpf is the standard that all other libraries and tools seem to build off of. The two exceptions are iproute2 and the Cilium project (which uses iproute2).
The iproute2 suite provides it's own BPF syscall wrappers and map definitions, along with it's own loader (exposed in both the ip and tc programs). The loader API and map definitions are slightly different than those used in libbpf and thus are incompatible except in the most simple of cases.
Unfortunately, iproute2 provides some additional features for it's own maps that offer more flexibility (namely filesystem and global pinning), and when combined with the ubiquity of ip and tc programs, means this API is probably not going away any time soon. There has been talk of merging the two APIs, however such work has not been done as of the time of this writing. Finally, easily accessing the Traffic Control layers of networking stack is done via the tc command, which expects the iproute2 interface.
The Cilium project is such a major player in the BPF ecosystem that it's endorsement of the iproute2 interface all but guarantees it's existence going forward.
Workflow
The general workflow of writing BPF programs is writing a small C (or Rust or Go) program which must follow the limitations of the verifier and will run directly in the kernel. As of yet, gcc does not provide a BPF target, so pre-compiled BPF programs (such as those following the iproute2 interface) usually use clang and output LLVM bitcode, which is then further compiled by llc into the actual ELF binary.
Thus, assuming a fictional BPF program written in C called bpf_prog.c would follow the following flow:
$ clang -O2 -emit-llvm -c bpf_prog.c -o bpf_prog.bc $ llc -march=bpf -filetype=obj -o bpf_prog.o bpf_prog.bc The result is a binary ELF bpf_prog.o. As noted earlier, the BPF bytecode and map definitions are stored in specific ELF sections as per the loader API (in this case we're assuming the developer used the iproute2 interface). We can see the section headers with llvm-objdump:
$ llvm-objdump -h bpf_prog.o bpf_prog.o: file format elf64-bpf Sections: Idx Name Size VMA Type 0 00000000 0000000000000000 1 .strtab 00000192 0000000000000000 2 .text 00000000 0000000000000000 TEXT 3 classifier 00000680 0000000000000000 TEXT 4 .relclassifier 00000040 0000000000000000 5 action-mark 00000088 0000000000000000 TEXT 6 .relaction-mark 00000010 0000000000000000 7 action-rand 00000098 0000000000000000 TEXT 8 .relaction-rand 00000010 0000000000000000 9 maps 00000048 0000000000000000 DATA 10 license 00000004 0000000000000000 DATA 11 .eh_frame 00000070 0000000000000000 DATA 12 .rel.eh_frame 00000030 0000000000000000 13 .symtab 000003d8 0000000000000000 Notice the sections maps and action-mark. The iproute2 interface states that all maps must be stored in the section maps, while the bytecode can be stored in arbitrary sections, so long as those sections only include BPF bytecode. In this case, the developer chose the name action-mark and action-rand as the section headers for the bytecode (which we would only know by looking at the bpf_prog.c file). We would need to know these sections names in order to tell either ip or tc which section of the ELF contains the bytecode that must be loaded and verified by the kernel.
An example of loading the above program via tc is a two step process, first creating a qdisc "classifier/action" (clsact) and then loading an ELF file and telling tc which section to load:
NOTE: What this program does is irrelevant at this point (remember it's just a fictional program), the purpose this is just to demo what it looks like to work with a BPF ELF binary loaded via ip/tc.
$ tc qdisc add dev eth0 clsact $ tc filter add dev eth0 ingress bpf da obj ./bpf_prog.o sec action-rand Or with ip it's a one step process:
$ ip link set dev eth0 xdp obj bpf_prog.o sec action-rand ─=≡Σ((( つ◕ل͜◕)つFuture Kevin SaysWait! For those familiar with BPF and XDP I can hear your screams now. We'll address the difference in a moment.
It is important to note that ip and tc are not interchangeable (even though it looks like I just demoed that they are). tc is used for BPF programs designed to be used with in the Traffic Control layer of the kernel networking stack, where as ip can be used to load programs targeting the XDP (eXpress Data Path) layer of the networking stack (more on this later).
When targeting other layers of the kernel (not just the networking stack) one must use custom loaders, use the libbpf loader API, or use special tools designed to assist in loading BPF programs such as bpftool.
A note on bpftool is an incredibly useful tool which can not only load BPF programs, but list currently loaded programs, dump their source, dump their assembly, list current maps in use, even read/write values to a map directly. Full use of this tool is outside the scope of this post, but as one gets into testing and working with BPF programs regularly, this tool should be invested in heavily.
BPF VM Internals
To clarify some the above in regards to "targeting" a particular point in the stack, or "using the iproute2 interface" let's take a step back and look at what makes up the BPF program long with a taste of the interfaces they consume.
Gory Details
The BPF VM that runs inside the kernel operates on opcodes and uses ten 64bit width registers and one read only register which are all labeled r# where # is a numeral 0 through 10. Some of the registers have special purposes, listed below:
-
r0is the return code from in-kernel/program exit -
r1-r5function arguments/scratch stack space (this means BPF has a limit of 5 function arguments, more on this below) -
r6-r7callee-saved -
r10read only frame pointer to stack space
The opcodes operating on these registers can be seen using objdump for pre-compiled ELF binaries (or by using bpftool prog dump for already loaded BPF programs), along with the more human readable variant:
NOTE: understanding the output below is not necessary. This is just an example of what the opcodes and their human readable output look like.
$ llvm-objdump --source bpf_prog.o [ .. ] 0000000000000850 : 266: b7 07 00 00 00 00 00 00 r7 = 0 267: 07 08 00 00 ff ff ff ff r8 += -1 268: 57 08 00 00 ff 00 00 00 r8 &= 255 269: 25 08 61 ff 04 00 00 00 if r8 > 4 goto -159 270: 67 08 00 00 02 00 00 00 r8 <<= 2 271: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 273: 0f 81 00 00 00 00 00 00 r1 += r8 274: 61 10 00 00 00 00 00 00 r0 = *(u32 *)(r1 + 0) 275: 95 00 00 00 00 00 00 00 exit [ .. ] The opcodes are the hex byte values listed with their offset to the left. To the right is what they map to in human readable text. To see just the human readable variant with the offset, include the --no-show-raw-insn
$ llvm-objdump --no-show-raw-insn --source bpf.o 0000000000000850 : 266: r7 = 0 267: r8 += -1 268: r8 &= 255 269: if r8 > 4 goto -159 270: r8 <<= 2 271: r1 = 0 ll 273: r1 += r8 274: r0 = *(u32 *)(r1 + 0) 275: exit The kernel takes that code and sends it through the verifier to ensure nothing dangerous or that could crash/hang the kernel is being performed. Once through the verifier the kernel optionally runs it through the JIT compiler (which can be controlled via /proc/sys/net/core/bpf_jit_enable) which outputs and runs native machine instructions meaning there is no additional performance overhead to running BPF programs beyond the few instructions they generate.
Finally for completeness sake, there is an assembly language variant for BPF which looks like:
ldh [12] jne #0x800, drop ldb [23] jneq #6, drop ret #-1 drop: ret #0 This can be compiled with llvm-mc or bpfc, however it appears less common except for extremely specific use cases where clang performs (or fails to perform) particular optimizations. This is an escape hatch so to speak and not meant to be used day to day.
So why did we go through all that?! The point is working with BPF directly is tough. Just like working with bare Intel opcodes is tough, we added asm, and then C on top of that. The layers of abstraction make working with the underlying technology easier. Likewise, layers of abstraction have been added on top of BPF.
BPF Source Programs
Most often, people write the BPF programs in C (or other languages with an LLVM back end) using one of the wrapper APIs as it's much easier to follow and understand than raw BPF opcodes or bpf(2) calls.
An extremely minimal BPF program (i.e. this does nothing but pass the network packet up the stack) targeting the XDP layer of the network stack looks like:
#include #include SEC("xdp") int xdp_prog_simple(struct xdp_md *ctx) { return XDP_PASS; } char _license[] SEC("license") = "GPL"; Important parts to note are:
- The function
xdp_prog_simplewhich contains the code that will be executed by the BPF VM (the function name is purely arbitrary) -
SEC("..")macro which defines which ELF section the function ends up in -
_license[]static variable which gets put in thelicensesection of the ELF, this is the what the kernel reads to determine if the BPF program is allowed access to certain BPF helper functions (none are in use in the above example) -
struct xdp_md *ctxis the "context" passed to the BPF program by the kernel
The section name as mentioned previously can be either arbitrary, or be required to be something specific depending on which loader you use.
The "context" gets us into the larger picture of how BPF sits in the kernel stack and what are the actual possibilities for a BPF program. BPF programs can be "attached" to various kernel attachment points. There are hundreds, or maybe thousands of these attachment points. When the kernel reaches a point in its execution to hit one of these attachment points, it passes control to the BPF program with some "context."
Since BPF programs are just small functions that run at multiple layers of the kernel or userspace, a diagram may look something like:
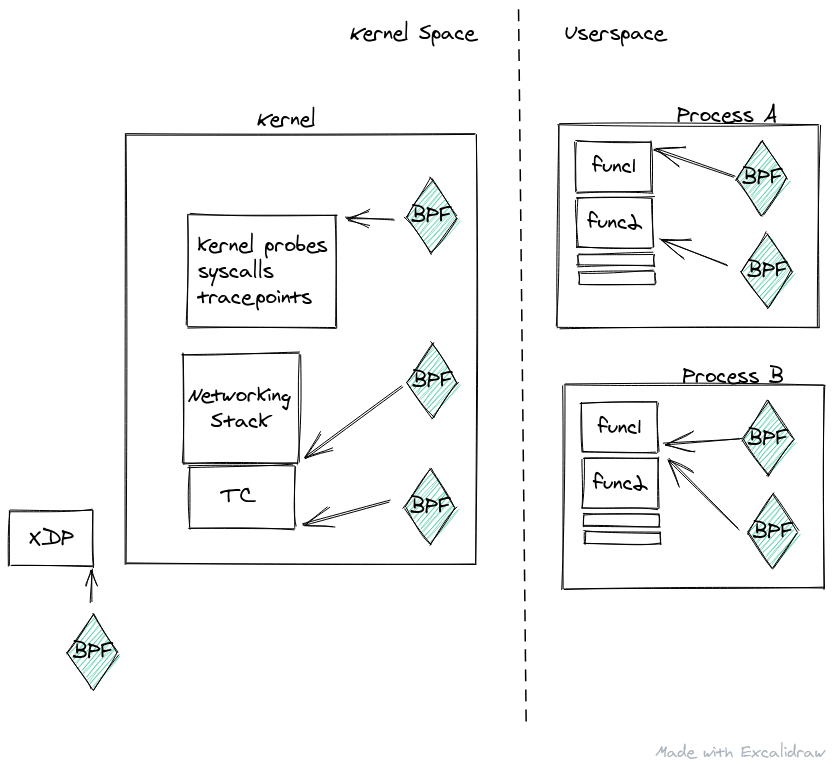
The context depends on the attachment point, and varies wildly. In some attachment points it, the context may provide insight into kernel data structures, or information about events surrounding the attachment point, or in other it may contain the actual data the kernel plans on using (or at least pointers to that data).
In the above example, as with all XDP BPF programs, the context is a data structure called xdp_md which points to a region of memory where a single network packet resides. This means the BPF program is called once for every network packet and given access to the memory of that packet.
At least in the XDP context, this means the BPF program can view or even re-write the packet data. In the case of XDP, this attachment point is extremely low level, and actually prior to the kernel conducting any processing on the packet at all.
Small side note, BPF programs targeting the XDP attachment point can even be offloaded on the actual NIC hardware, for some special NICs. This means the BPF program is loaded onto the NIC, and run for every packet that touches the NIC before the host machine/kernel even sees it. This is incredibly powerful as if the goal is simply to drop, or re-route the packet it means you do not waste any of the kernels valuable resources allocating memory and parsing packet data for no reason.
Back to the XDP context, once the BPF program exits, it can signal to the kernel what should be done with the packet, either passing it up the network stack for normal processing, dropping, or re-routing back out into the network. If the packet is modified in any way during this layer, the kernel does not know anything about that modification, it simply believes the packet arrived off the NIC in that manner.
XDP can also add some special metadata to the memory next to the packet which can then be read by the Traffic Control layer of the networking stack, which is next in line.
For example, packet ingress flow may look something like this:
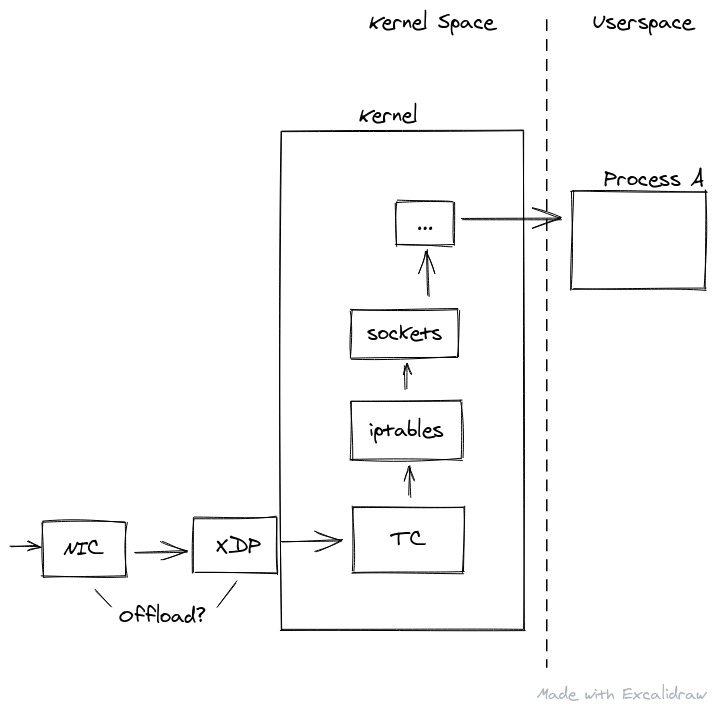
The traffic control layer gets the packet after the XDP layer, but first the kernel does some basic parsing of the packet memory and allocates a socket buffer. Thus the context is different from the XDP layer, so a function targeting the TC layer would look like:
SEC("action-drop") int tc_prog_simple(struct __sk_buff *ctx) { return TC_ACT_SHOT; } This means at this attachment point, you've allowed the kernel to spend a few resources on this packet, but in exchange you have access to a more rich set of information about the packet hence the different context. Instead of just a raw area of bytes, the __sk_buff struct provides a lot of info about the packet itself as well as which interface it arrived on, priorities, etc.
Additionally, BPF programs at this layer can be attached to the ingress or egress side, whereas XDP BPF programs only have access to the ingress side.
Like XDP, the TC layer can read/modify data in the packet and decide what to do by either passing the packet into the actual kernel networking sub-stack, dropping, or re-directing. However, unlike the XDP layer, the TC layer must use special BPF helper functions to modify the packet and does not have direct packet memory access. This layer is still lower than the normal kernel network stack, including prior to any iptables chains or tables.
If the XDP program had added special metadata to the packets memory, it is stripped by the kernel after the TC layer. This means the TC layer has access to it, and can make decisions or perform actions as signaled by the XDP layer.
Attachment points for further up the stack likewise have different contexts and possibilities. Some such attachments are when the kernel is deciding on which socket to send a particular traffic to, etc.
Beyond networking, common attachment points are upon standard syscalls where the BPF program runs at either the beginning (kprobe) or end (kretprobe) of a kernel function. These attachment points are given a context such as the function arguments passed to the syscall, or return code. Like the network layers, these BPF programs can either signal to the kernel to take action, or even modify the function arguments (assuming running prior to the syscall) before the syscall takes place.
One can use these powers to either trace kernel actions by simply logging what is going on, or even implement security features by blocking actions from happening based on certain contexts. In fact this is how some security tools and sandboxes function, by monitoring kernel functions with BPF programs and denying access based on some condition.
But it's not just kernel functions that can be attached to/traced its also userspace functions via uprobe (prior) and uretprobe (after), or tracepoints. The details don't matter too much right now, but the difference between all of these options boils down to whether or not the developer of the userspace function pre-wrote in some BPF hook points or not.
Beyond Standard BPF Programs
Two other terms come up when researching BPF and that is bpftrace and BCC. It can be confusing how these fit into the larger picture as many people will get pointed to these projects as their first foray into BPF.
BCC
Starting with BCC since it fits closest to the items we've already discussed. BCC stands for BPF Compiler Collection and sits on top of libbpf to provide language API surfaces for loading/executing and read/writing to maps as well as compilation of inline BPF programs.
What that mouthful means is one could write a Python script, with some small inline C program embedded as a string. Then use the BCC Python API surface to compile the inline C, load the resulting BPF bytecode, and communicate with the BPF program via reading and writing to any defined maps.
An example BCC program in Python looks like:
from bcc import BPF c_prog = """ int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; } """ bpf = BPF(text=c_prog) bpf.trace_print() Similar language surface APIs exist for other languages as well, notably Go.
Where this gets confusing (beyond the need for inline C) is that the BCC project maintains a set of examples which double as a set of actually usable tools. These examples showcase how to use BCC as well as the capabilities, yet are also fully functional and useful tools.
So some get pointed at BCC as a collection "bpf tools" while others get pointed to BCC as a library/framework for writing BPF programs directly.
bpftrace
bpftrace is a tool that takes small scripts and turns them into BPF programs and loads/executes them directly. It provides a small C like DSL (Domain Specific Language) which it then takes and compiles into BPF bytecode (via libbpf) and loads/runs. bpftrace also provides a bunch of pre-built visualization primitives for getting data out of these ephemeral BPF programs, such as histograms and counters.
bpftrace allows one to write these small bpftrace scripts and execute them much in a manner like one would use bash to execute a Bash script, or it can be used to write so called "bpftrace one-liners" where the entire script is included in a single command. This is possible because the DSL takes care of most of the boilerplate, and that bpftrace is primarily aimed at tracing BPF programs (hence the name) as opposed to network (or higher level) mangling BPF programs.
An example bpftrace one-liner looks like:
$ bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }' Again, to make matters confusing bpftrace also contains a collection of examples which double as actually useful tools, and many of which are clones of the BCC tools. Again, some people get pointed to bpftrace as a collection of useful low level introspection tools, while others get pointed to it as a means to write small BPF tracing programs without needing to know how to write full fledged BPF programs. This is not to knock bpftrace as somehow less than "full" BPF programs. Many of the tools bpftrace contains are extremely useful fully self contained!
Conclusion
The above barely scratches the surface of BPF and what it has to offer. Unfortunately, being such a low level technology inside the Linux kernel, it is a tough topic to cover and requires deep knowledge in specific areas. Hopefully it is slightly more clear where this technology sits in the stack and deep the rabbit hole goes. If nothing else, I hope this document serves as jumping off point or clarification of this somewhat confusing space.
In short, BPF programs are small programs that safely run inside kernel space at specific attachment points, firing at specified events. These programs can log (trace), alter, or even redirect kernel structures in combination with larger userspace programs.
Getting all this power of kernel speed processing/access without the need to recompile a custom kernel, or create a kernel module and have the code executed in guaranteed safe manners is game changing!
See Also
The following is a small subset from awesome-ebpf
Reference Documentation
eBPF Essentials
- ebpf.io - A gateway to discover all the basics of eBPF, including a listing of the main related projects and of community resources.
- Cilium's BPF and XDP Reference Guide - In-depth documentation about most features and aspects of eBPF.
Kernel Documentation
- BPF Documentation - Index for BPF-related documentation coming with the Linux kernel.
- BPF Design Q&A - Frequently Asked Questions on the decisions behind the BPF infrastructure.
- HOWTO interact with BPF subsystem - Frequently Asked Questions about contributing to eBPF development.
Manual Pages
-
bpf(2)- Manual page about thebpf()system call, used to manage BPF programs and maps from userspace. -
tc-bpf(8)- Manual page about using BPF with tc, including example commands and samples of code. -
bpf-helpers(7)man page - Description of the in-kernel helper functions forming the BPF standard library.
Tutorials
- bcc Reference Guide - Many incremental steps to start using bcc and eBPF, mostly centered on tracing and monitoring.
- bcc Python Developer Tutorial - Comes with bcc, but targets the Python bits across seventeen "lessons".
- Tracing a packet journey using Linux tracepoints, perf and eBPF - Troubleshooting ping requests and replies with perf and bcc programs.
- XDP for the Rest of Us - Second edition, with new contents.
- Load XDP programs using the ip (iproute2) command
- XDP Hands-On Tutorial - A progressive (three levels of difficulty) tutorial to learn how to process packets with XDP.
Examples
- linux/samples/bpf/ - In the kernel tree: some sample eBPF programs.
- linux/tools/testing/selftests/bpf - In the kernel tree: Linux BPF selftests, with many eBPF programs.
- prototype-kernel/kernel/samples/bpf - Jesper Dangaard Brouer's prototype-kernel repository contains some additional examples that can be compiled outside of kernel infrastructure.
- iproute2/examples/bpf/ - Some networking programs to attach to the TC interface.
- Netronome sample network applications - Provides basic but complete examples of eBPF applications also compatible with hardware offload.
- bcc/examples - Examples coming along with the bcc tools, mostly about tracing.
- bcc/tools - These tools themselves can be seen as example use cases for BPF programs, mostly for tracing and monitoring. bcc tools have been packaged for some Linux distributions.
- MPLSinIP sample - A heavily commented sample demonstrating how to encapsulate & decapsulate MPLS within IP. The code is commented for those new to BPF development.
- ebpf-samples - A collection of compiled (as ELF object files) samples gathered from several projects, primarily intended to serve as test cases for user space verifiers.
eBPF Workflow: Tools and Utilities
-
bcc - Framework and set of tools - One way to handle BPF programs, in particular for tracing and monitoring. Also includes some utilities that may help inspect maps or programs on the system.
-
iproute2 - Package containing tools for network management on Linux. In particular, it contains
tc, used to manage eBPF filters and actions, andip, used to manage XDP programs. Most of the code related to BPF is in lib/bpf.c. -
libbpf - A C library used for handling BPF objects (programs and maps), and manipulating ELF object files containing them. It is shipped with the kernel and mirrored on GitHub.
-
bpftool - Also some other tools in the kernel tree, under linux/tools/net/ for versions earlier than 4.15, or linux/tools/bpf/ after that:
-
bpftool- A generic utility that can be used to interact with eBPF programs and maps from userspace, for example to show, dump, load, disassemble, pin programs, or to show, create, pin, update, delete maps, or to attach and detach programs to cgroups.
-
Other Lists of Resources on eBPF
- IO Visor's bcc documentation
- IO Visor's bpf-docs repository
- Dive into BPF: A List of Reading Material
Discussed this post on DEV.to!