eBPF and Rust (Part 4)
This is a multi-part series on my adventure into eBPF with Rust.
In part 4 do a deep dive into the current implementation of redbpf-probes networking code in order to mark areas we want to look at for improvement.
- Part 1: we lay out the problem set
- Part 2: we dive into eBPF in a general sense to familiarize ourselves with the technology before reaching out to Rust
- Part 3: we look at current state of eBPF networking in Rust and what it would look like to solve our Part 1 problem
- Part 4: We do a deep dive into the current networking implementation of
redbpf-probesand note areas we want to improve - Part 5 (Coming Soon): We propose ideas for improving the
redbpf-probesnetworking modules
Current lay of the land
NOTE: Before we start I need to disclaim that this post/series is NOT//NOT a critique of redbpf-*! This is simply my observations for my own use case, with ideas for improvement. The developers of RedBPF are extremely professional, and my going back and forth with them over chat I can assure you they are also extremely proficient and running laps around me at low level code (especially when it comes to things like LLVM code generation and other topics that make the hair on the back of my neck stand up!).
First, we need to acknowledge what our state of affairs is, and what our goals should be before we can address whether or not our goals are being met and if we can improve on methods to achieve them.
Let's look at how it currently works under the hood. We will be spending 99% of our time in redbpf-probes because that's where the majority of the networking code lives. We may hop over to the companion crate redbpf-macros for a brief time since although a companion it's basically essential to using the networking modules in redbpf-probes. Once we get a feel for where we are we'll have a better idea of any shortcomings, if any. If we do find areas we'd like to modify I won't mention any specific changes I'd make just yet, and will wait until I'm done walking through the current implementation so as not to get side tracked down any rabbit holes with possible details on implementation ideas.
XDP Entry Point
Like all good programs, we must start somewhere. Unlike a traditional binary that we'd execute on the host machine, BPF programs don't usually have a main() function. Instead, we have various code sections of the ELF binary that the kernel will run directly, which is typically a function (or multiple functions that have been inlined into a single function) of some form. This means we only need to define a function with a correct signature, and tell the kernel where it's located in the final ELF binary.
In redbpf-probes we define our entry point function by tagging it with the attribute #[xdp]. This attribute is a procedural macro that performs a few useful tasks.
The #[xdp] macro is defined in redbpf-macros. Of the tasks it performs for us, perhaps most importantly it wraps our user function in an outer function with the correct kernel BPF API.
It then places this outer function in a particular ELF section (the section name xdp/foo [where foo is our inner function] is used arbitrarily). Next this macro takes the kernel context pointer which is a raw pointer (*mut) to an xdp_md struct and wraps it in a more friendly redbpf-probes type before handing that to our inner function. The new type is called XdpContext which is the actual value that gets passed to our inner function. This new type allows redbpf-probes to implement additional methods and functionality on top of the raw pointer handed out by the kernel.
The outer XDP function also takes the return value we (inner function) finish with and performs a match on it, turning this value into something BPF can understand. It's worth noting that if we return an Err variant, it will get translated into XdpAction::Pass (accept packet and continue up the networking stack).
If you're not into procedural macros, no worries the simplified expansion of our #[xdp] marked function foo() is the following:
#[no_mangle] #[link_section = "xdp/foo"] fn outer_xdp(ctx: *mut xdp_md) -> XdpAction { let ctx = XdpContext { ctx }; return match foo(ctx) { Ok(action) => action, Err(_) => XdpAction::Pass }; fn foo(ctx: XdpContext) -> XdpResult { // our code here ... } } In this post we'll dive into all the pieces that make up the above expansion, as well as the components that make up our example BPF program from Part 3 as well.
First up, let's start with that new type XdpContext given to us by the outer function.
The XdpContext struct
At the beginning of our inner function, we're given an instance of XdpContext where the inner value is pointer to a binding of a C struct xdp_md. The xdp_md struct contains a couple of values that'll we'll be interested in, but only two are used in redbpf-probes, the data and data_end fields which are addresses in memory (not pointers) for the beginning and end of the packet memory.
This means the XdpContext struct wraps a pointer, which itself contains "pointers" directly to packet memory. Unlike other contexts we'll see later on, the memory addresses within the range pointed to by these fields is directly mutable.
The XdpContext struct doesn't provide a whole lot on top of the xdp_md struct, just a method to retrieve the inner raw pointer to the xdp_md struct. It does however implement a trait that lets us do a lot more with that memory.
The NetworkBuffer trait.
The NetworkBuffer trait
The current design of the networking portions ofredbpf-probes in a way revolves around the trait NetworkBuffer. Its purpose is to represent abstract functionality for any buffer of network memory as described by two memory addresses (for the beginning and end of the buffer).
This trait allows a type to implement accessing raw pointers and memory of the buffer (with some basic bounds checking math), and also some convenience methods for retrieving pointers to specific header structs that may be contained in the buffer itself. This is all done via pointer arithmetic to increase or decrease the addresses of either the beginning or end of buffer.
Wait, what is a network packet?
Let's take quick step back and look at what a network packet is made of first.
You can think of a network packet as a "header" followed by a "body/payload".
Future Kevin SaysI use the terms body and payload interchangeably. As well as the terms header and prefix.¯\_(ツ)_/¯
The header lays out a very strict set of packed fields/values along with their byte offsets. In this way we can pack as much information into as few bytes as possible without having to waste space (bandwidth) on sending "useless" data such as things like padding. Directly after the header starts that particular packet type's body.
The body, is many times an encapsulated header of another type, along with another inner body. These header/body encapsulations can continue for an arbitrary depth until you reach the final body/payload which is the application data being transmitted.
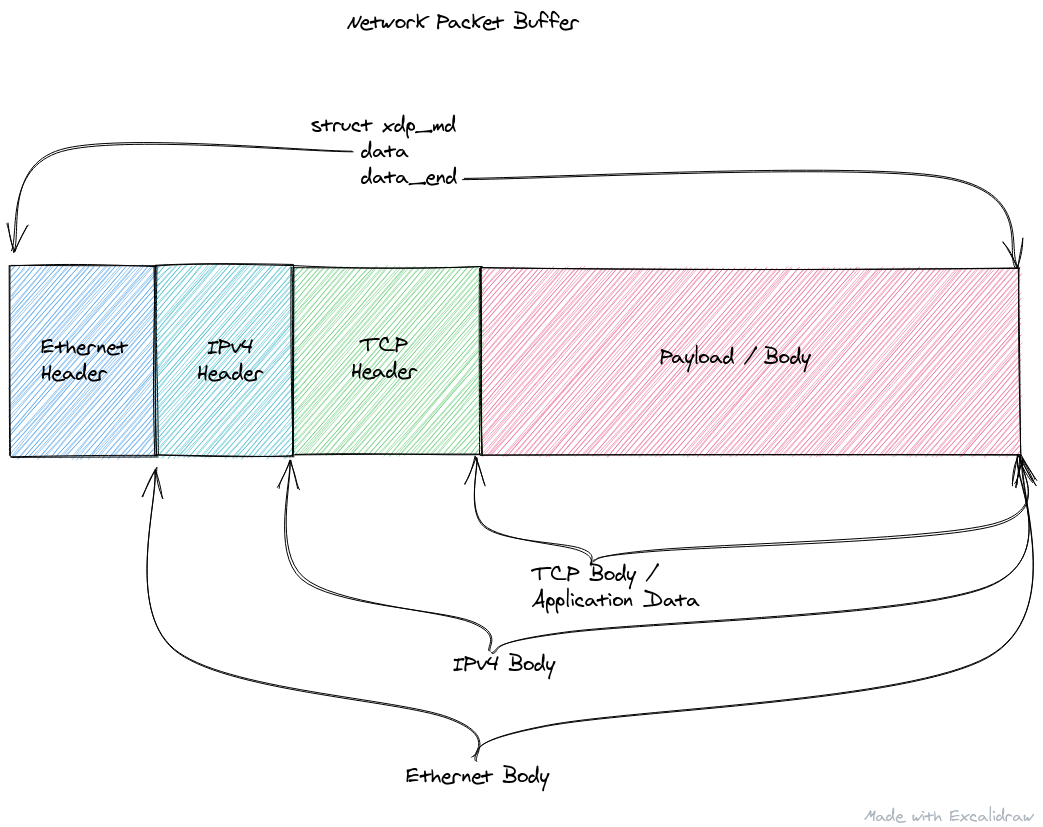
Headers can be various sizes depending on the protocol they're representing, and almost all of them have varying fields. The total packet size (so all the headers + the final body) is limited by the Maximum Transmission Unit (MTU) for a given network medium. For example with Ethernet and it's family that is 1500 bytes. So we can't really just recursively encapsulate forever, or we'd not have any room left for the actual application data.
If we have application data that is too large for the space left (after all headers have been encapsulated) that data can be broken up into multiple network packets at either the application level (which is preferred), or the network level (known as packet fragmenting).
There are also minimum packet sizes, such as 64 bytes for Ethernet, so there are instances were we could end up adding padding of some sort to the final body if the application data was extremely small.
All this talk of "levels" means I should bring up the OSI networking model; which defines nice delineations of responsibilities for a typical network packet. When creating a network packet (i.e. the bytes are being written to a buffer by the application or OS) it's standard to first have a "layer 2" header, followed by a "layer 3" header, and finally a "layer 4" header whose body contains the application data.
If you're not familiar with that model, it's OK, it's just to say for example an Ethernet packet will encapsulate a IPv4 packet, which will encapsulate a TCP packet, who will encapsulate the application data. The layers just refer to how the model stacks the protocols and where they fit in the abstraction stack.
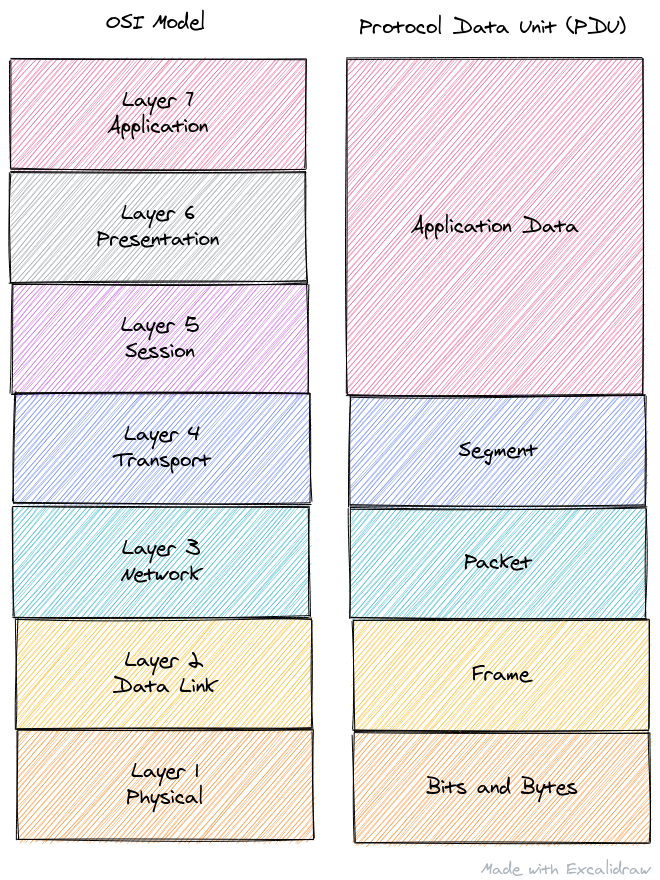
In the above image "packet" can be confusing because the term is overloaded, but it only refers to "layer 3" protocols. Also note that layer 1, "physical" is the actual bits on the wire and not something we are concerned with while parsing network packets. We're primarily concerned with layers 2 through 4, and final body/payload which makes up layers 5 through 7 which the application is responsible for.
Accessing Raw Headers in a NetworkBuffer
When we have a raw network buffer, we'll most likely want to find out what the first header is, so we can start to do some further parsing.
At least for the first header, we can make an educated guess at type of header based off the network medium the packet is coming from. For example, if we're attaching this XDP program to an ethernet NIC, chances are good (if not certain) the packet's first header is an Ethernet (802.3) header. Likewise, if we're attaching this XDP program to a wireless NIC, chances are good (if not certain) the first header will be an 802.11 header for Wireless LAN
redbpf-probes currently only supports Ethernet (802.3) out of the box, one would have to parse the bytes as another header type manually.
For example, the trait provides NetworkBuffer::eth which returns Option<*const ethhdr> by trying to interpret the first few bytes of the buffer as an Ethernet (802.3) header and gives back a raw constant pointer on success or an Err otherwise.
But what constitutes success? Currently, the only way to fail this is not if the packet does not contain an Ethernet header, but instead if the packet buffer is too small to contain an Ethernet header. So long as the packet contains enough bytes to hold an Ethernet header, the bytes will be interpreted as an Ethernet header (*const ethhdr) regardless of what the actual bytes were supposed to represent.
This means validation of any kind is left to the caller.
Other methods on the trait do similar, such as NetworkBuffer::ip which assumes the first few bytes of the buffer are an ethernet header, then tries to parse the next few bytes as an IPv4 header giving out a raw constant pointer on success.
This method does a little bit of validation, because as part of the Ethernet header, there is a field that lists the encapsulated packet type. If the field is anything other than IPv4, an Err is returned. Like the NetworkBuffer::eth method, having a packet that is too small to contain both an Ethernet and IPv4 header will be considered invalid and return None as well.
Further down the list we see two interesting methods, as they don't return raw pointers (at least on first glance); NetworkBuffer::transport and NetworkBuffer::data.
Transport Headers
We'll first look at NetworkBuffer::transport which we're using in the example code in Part 3. It returns an enum where each variant is a tuple struct with an inner value of a raw constant pointer to some type of transport protocol header (such as TCP or UDP).
This enum provides access methods to both source and destination ports since both TCP and UDP utilize such.
Like the NetworkBuffer::ip method, it also uses the built in IPv4 header fields to determine which type of packet it is encapsulating, and returns the appropriate variant, as well as the standard size checking like all previous methods.
Payload Data
Finally, NetworkBuffer::data returns a new struct we haven't seen yet called Data which represents a packet payload after all the known headers. An interesting note about Data is that it's generic over some type T that implements NetworkBuffer, which is essentially XdpContext or SkBuff (which we haven't discussed quite yet, but will shortly).
Also, the way a Data is created is by first matching on the NetworkBuffer::transport return, and then calculating a base address of the payload after the headers. If you'll remember from just a moment ago, to get the Transport enum, we first make the assumption that the packet contains an Ethernet and IPv4 header.
The type Data itself provides a few basic methods for getting the current offset from the base of the packet memory, viewing this data as a Rust slice, and perhaps most interestingly reading raw bytes into a NetworkBufferArray. As it turns out NetworkBufferArray is just a marker trait for byte arrays of 512 bytes or smaller (and is our second/final tiny dip into redbpf-macros).
Recursive Packets
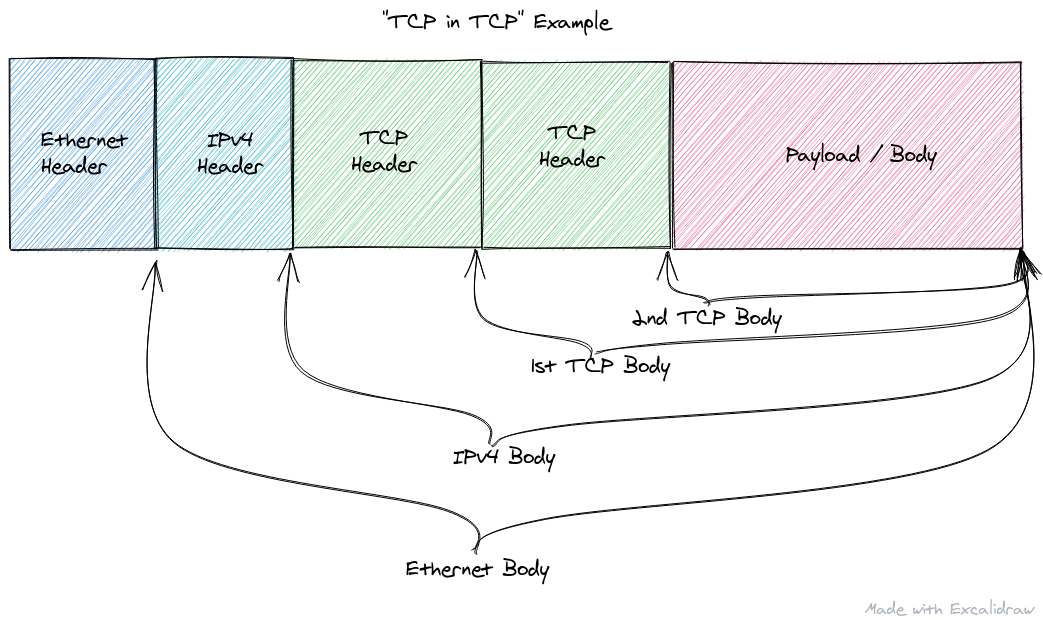
It's important to note that Data requires that T implement NetworkBuffer. In theory this should allow us to parse recursive packets which is something is somewhat common in network traffic. A recursive packet is instead of the traditional Layer 2 containing Layer 3 which contains Layer 4 (as I'll abbreviate L2->L3->L4, where -> means "contains" or "encapsulates), a layer contains either another header of the same layer, or potentially even a layer above itself. For example, where a TCP payload contains another TCP header, or an IPv6 payload contains an IPv4 header (which then contains something like a UDP header, etc. etc.).
However, while parsing down the headers past the first layer 4 header (i.e. TCP or UDP), there doesn't seem to be an easy way to get a new NetworkBuffer of just the payload region where all the pointer addresses are pointing to the new "base" (i.e. what was the payload) so that we can continue to parse headers. And even if there were, because the current implementation assumes the headers are strictly L2->L3->L4, there is not easy way (i.e. not manual) to parse a packet that is something like L2->L3->L4->L4 or even L2->L3->L3->L4->L4.
For example, the L2->L3->L4->L4 mentioned above, may look like this if the packet was a "TCP in TCP" packet (Note, this is generally a bad idea...but sometimes things like this are required or unavoidable):
SkBuff
The final piece to talk about is SkBuff which is the sibling to XdpContext except for Socket or TC BPF programs. Instead of a *mut xdp_md, it wraps a *const __sk_buff. If you'll glance back at part 2, __sk_buff is the struct context that is created once the kernel has done some basic parsing of the packet data, and allocated some memory to hold a sk_buff struct (Socket Buffer). BPF programs aren't given direct access to the packet memory anymore, and instead are given the __sk_buff which mirrors the kernel's in memory sk_buff struct. In order to mutate the contents of the actual packet, one must call the bpf_skb_write_bytes helper function.
The SkBuff struct provides one method, SkBuff::load for reading raw bytes out of the internal buffer by offset.
Because the bytes pointed to in either the XdpContext or SkBuff are networking bytes, they are stored in "network byte order" (Big Endian) and must be converted to "host byte order" (which is often Little Endian, but determined by platform). SkBuff::load takes care of the conversion for us, but XdpContext, NetworkBuffer, or Data do not, and leave that to the calling code.
NOTE: A full discussion on Endianness is beyond the scope of this series (see here for a quick intro), but essentially it's the order in which bytes are stored (least significant bits first is Little Endian, and most significant bits first is Big Endian).
Wrap Up
Now that we've done a good quick deep dive of what's currently implemented and available in the RedBPF networking modules, we can begin to look at improvements we could make in the next post!
Discussed this post on DEV.to!